Published dispatch May 20, 2026
Context as core infrastructure
Pay attention to your context and treat it as essential operational infrastructure, not just per-session management.
I have become much less interested in prompt cleverness over the last few months. What I care most about right now is approaching deterministic behavior in messy, non-deterministic agent loops. I want this determinism regardless of the intelligence of the model and independent of where the agent happens to be running. Much of that, with today's LLMs, seems to come down to context control.
Filed
May 20, 2026
Published on galexc.me/dispatches
Read time
13 min
Agent systems, with real detail.
Tags
Editorial note
Co-authored by Gilman and GalexC.
Building with LLMs in agent harnesses is wildly productive when it works. However, we've all now seen that some issues show up rather quickly. Chief among them: "this worked yesterday!" A workflow that worked great yesterday starts behaving oddly, tool calls fail when they shouldn't, the entirely wrong tools are called, the agent starts writing one-off scripts to "fix" the problem, etc. Many are quick to blame the model, which is natural given that it is the most exposed toggle we see in most harnesses right now (e.g. switch between GPT 5.5 and Opus 4.7).
It is increasingly clear that, today, most of the real problem is the context.
Common scenario: lax startup context → low control → high variability → goofy stuff happens.
Of course, this matters for reasons beyond the wasted tokens. I've seen a common pattern where, once a session begins feeling weird, people stop asking what changed in the instructions, the routing, or the startup surface. Instead they start treating one lucky model choice like the only safe option. This limits productivity, hampers your ability to confidently test different models, and locks you in to specific vendors more and more.
Approach context management as a real operating concern.
To me, this means I have confidence that my systems run as I expect them to (both live and headless). This requires a combination of sharper startup files, multilayered routing, reusable skills, recurring expertise harvests, and visible startup-context feedback in Pi (my harness of choice) so the context surface stays front and center instead of disappearing into the background.
I am currently treating context as a core infrastructure element that I need to own
If you haven’t already, I recommend reading Mario’s post on his learnings while building the initial version of Pi from late 2025. I’ll cherry-pick one paragraph here:
I’ve also built a bunch of agents over the years, of various complexity. For example, Sitegeist, my little browser-use agent, is essentially a coding agent that lives inside the browser. In all that work, I learned that context engineering is paramount. Exactly controlling what goes into the model’s context yields better outputs, especially when it’s writing code. Existing harnesses make this extremely hard or impossible by injecting stuff behind your back that isn’t even surfaced in the UI.
This was written in November 2025 and is still true today in May 2026. With the pace of progress in this field, that’s nearly a lifetime ago. And yet, this particular point is almost getting worse. The vast majority of agent harnesses are actively working to obscure away the context management layer and essentially telling users, “we got this, nothing to see here, it will just work like magic!”.
To be fair, the leading harnesses (e.g. Claude Code, Codex, Gemini, Hermes, etc.) are incredibly capable. And, indeed, likely the best solution for the majority of use cases. My friends over at Command Code are also building something super cool and have a strong set of opinions around hackability and context management (along with some sophisticated harness-driven tooling to unlock full potential of various models).
That said, I’m still on the Pi-train primarily for two reasons:
- true hackability (my workstation sessions can be identical to my headless async agents, doing exactly what I need them to do)
- context management (extreme control over context in…any context)
This is interesting to me because with today’s models, bloated context almost never fails in a dramatic way. These models are good. So your system begins to fail in far more subtle ways.
- Taking a bit longer than it should (wasting tokens and time)
- Writing wacky one-off scripts to “address the problem” (unstable, unreliable, unpredictable)
- Arriving at outcomes that are close…but not exact (which brings you back to step 1)
A model that routed cleanly last week starts missing an obvious workflow. A reviewer starts hallucinating file paths. A session that should have felt deterministic feels mushy instead. If you run enough sessions, especially across multiple models, you can feel the variance climb long before you have a neat benchmark for it.
A few months ago I stopped thinking about context as “I just need to dial in THIS prompt” and started treating it more like reliability engineering. If the operating surface is sloppy, the system will look nondeterministic even when the underlying models are fine.
Learn from the best
A few weeks ago I decided to take this even more seriously. I kicked off GalexC on a research task to look at what the best in the world are publishing on this topic, and see what I could integrate into the system.
Exact prompt I gave to GalexC
That tiny prompt produced a lot more than a hand-wavy summary. GalexC went out and pulled first-party guidance from OpenAI Codex, Anthropic, Cursor, and Aider, then came back with a synthesized operating pattern instead of a pile of links.
| galexc produced | why it mattered |
|---|---|
| first-party research | Gave me confidence that I could refine a GalexC-specific direction that was grounded in the current state of the art. |
| synthesized patterns | Identified common signals across all evidence, primarily showing that the better systems were converging on the same startup shape. |
| concrete direction | Provided evidence and grounded intel to design a GalexC-specific context surface that leverages the field’s current state. |
| useful outcome | Among other things, I turned this research into a new /audit-context prompt+skill that ensures ongoing improvements. |
The pattern was consistent.
- Keep startup context small and layered.
- Put local instructions in version-controlled files.
- Retrieve aggressively just in time instead of preloading everything.
- Handle long-horizon continuity through summaries, notes, and subagents rather than dragging giant always-loaded prompts from session to session.
That single prompt did not give me the finished GalexC design. What it gave me was something almost more useful: a grounded read on where the best systems are converging, plus enough confidence to turn the next step into a real piece of infrastructure instead of another note to myself.
Focus on routing and expertise ownership, not just compression
I often fixate on compression, so that is table stakes at this point and I will keep doing that.
Interestingly, though, when I dug into my setup, the real opportunities for optimization seemed to come from duplicated/redundant routing language spread across the startup files.
With that, a major improvement to “determinism” in my system has come from clarifying ownership of behavior, tasks, and routing. Today, my startup context is extremely thin:
AGENTS.md -> standard behavioral contract (~4,000 characters, 90 lines)
.pi/AGENTS.md -> Optional Pi runtime delta (can be repo-specific, typically quite small)
docs/ROUTER.md -> well-structured pointer to where real detail lives for any "thing"
... -> As many other turtles below as necessary.In a nutshell, AGENTS.md carries the essential context contract and the hard rules. .pi/AGENTS.md carries the Pi-specific delta. docs/ROUTER.md owns the fuller route map, which means the other two files do not have to keep repeating it in slightly different words. Then there are other domain-specific routers below that, which of course depends on the task at hand.
GalexC’s actual docs/ROUTER.md
# Documentation Router
Use this compact router first. Load `docs/INDEX.md` only when you need the full inventory or need to update it.
## Core routing
### Architecture and design
- Architecture, topology, and roadmap: `docs/design/`
- ADRs: `docs/decisions/`
- Iterative design for LOE 3+: `docs/design/ITERATIVE-DESIGN.md`
### Operations runbooks
- Services and deployment: `docs/runbook/services.md`
- Ansible: `docs/runbook/ansible.md`
- Dispatch: `docs/runbook/agent-dispatch.md`
- Forge: `docs/runbook/forge.md`
- Agent incidents: `docs/runbook/agent-incidents.md`
- Docker, backups, Proxmox, storage, monitoring, Drive, Calendar, Gmail, Obsidian, and Chronology: `docs/runbook/`
### Colocated docs
- Roles: `ansible/roles/<role>/README.md`
- Hosts: `ansible/host_vars/<host>/README.md`
- Apps: start with `apps/<name>/CLAUDE.md` then `apps/<name>/AGENTS.md`. Prefer concise canonical app names under `apps/`. During a rename migration, route through the current on-disk path until the move lands.
- Hub: `apps/hub/CLAUDE.md` then `apps/hub/AGENTS.md`
- Real-world examples: `docs/real-world-examples/`
## Domain first stops
- Dispatch: `dispatch-lifecycle`, fallback `docs/runbook/agent-dispatch.md`
- Tasks: `task-lifecycle`, fallback `.pi/skills/task-lifecycle/SKILL.md`
- Search: `search-tailnet`, fallback `just meili search`
- Drive: `google-drive`, fallback `docs/runbook/drive.md`
- Forge: `docs/runbook/forge.md`, fallback `.pi/AGENTS.md`
- Hub: `apps/hub/CLAUDE.md`, then `apps/hub/AGENTS.md`. Infrastructure role and service identifiers may still use `hub-web` until a later migration.
- Real-world examples: `docs/real-world-examples/README.md`
- Services and Ansible: `docs/runbook/services.md`, `docs/runbook/ansible.md`, then colocated role and host READMEs. Python rollout nuance on `pve-worker-01`: `just ansible provision-role` updates env and templates but does not pull latest repo code. Runtime Python updates reach the worker through the updater service.
- Roles and hosts: colocated READMEs, fallback `docs/INDEX.md`
## Search-first shortcuts
```bash
just meili search "<query>"
just meili search-obsidian "<query>"
just meili search-dotfiles "<query>"
just meili search-all "<query>"
just tasks search "<query>"
```You’ll notice that the router is consistent and concise. It points to the next layer of context to load. You’ll also notice that it provides a clear searchable surface, which has been a big performance benefit over ripgrepping everywhere.
Brief aside on other harnesses: I normalize on AGENTS.md. For non-Pi harnesses, I use their convention (e.g.
CLAUDE.md) and literally just say,See [AGENTS.md](./AGENTS.md) for all project context, conventions, and principles.
What I like about the current system
One of the most interesting parts of this system to me is that it does not conflate ongoing system improvement with startup context. The startup context should not change very much, actually. Primarily the updates happen when entirely new GalexC features emerge. The system, of course, is improving all the time, and that’s where proper routing pulls its weight: those improvements are only injected into the agent context when necessary for the task at hand.
I have seen a lot of techniques/systems attempt to smoosh all of your history into the harness context, largely because it feels safer to keep everything around. While conceptually simple, that gets expensive both in token use and in wasted time/incorrect behavior/etc. In a nutshell: It makes your agents heavier, duller, and harder to reason about.
A note on search
There are diverging schools of thought on how to handle search across your AI surface. On one hand, Markdown has become the language of AI for now: super simple, basic text, generally lightweight, transportable, etc. So one approach is to believe that ripgrep is super fast, you already have this stuff in markdown anyway, so you should let these models do what they’re good at: search/find/read markdown files.
I fully agree with this approach if you’re working on isolated repos or narrowly scoped projects. I disagree with this approach if you’re building a personal AI that touches many different domains and needs to search across many different sources.
For GalexC, I’m a huge fan of Meilisearch right now, which gives me a single, extremely fast surface to search across anything I want. I can do full-text search now in about 0.5s across:
- all of my repos
- my obsidian vault
- gmail
- google drive
- the list goes on…
And they all have the same basic interface:
just meili search "<query>"
just tasks search "<query>"A note on skills
This is out of scope for a detailed review in this post but I will note that an essential part of my workflow is proper use of Skills and ongoing expertise. If I need method, I load a skill. If I need durable judgment, I pull the relevant expertise. If I need a broader audit of the startup surface itself, I run galexc-context-audit (skill) through /audit-context (prompt).
That matters because expertise is where repeated lessons stop being transcript mass and start becoming smaller operating surfaces. A good recent example was reconciling overlapping expertise-harvest PRs so unique findings were not lost across stale branches. The goal is not to remember everything forever. The goal is to keep the sharp parts.
How this impacts my day-to-day
Right now I look at my startup prompt token/character count eery session. This is just part of my workflow now so I can quickly tell when if has crept upward.
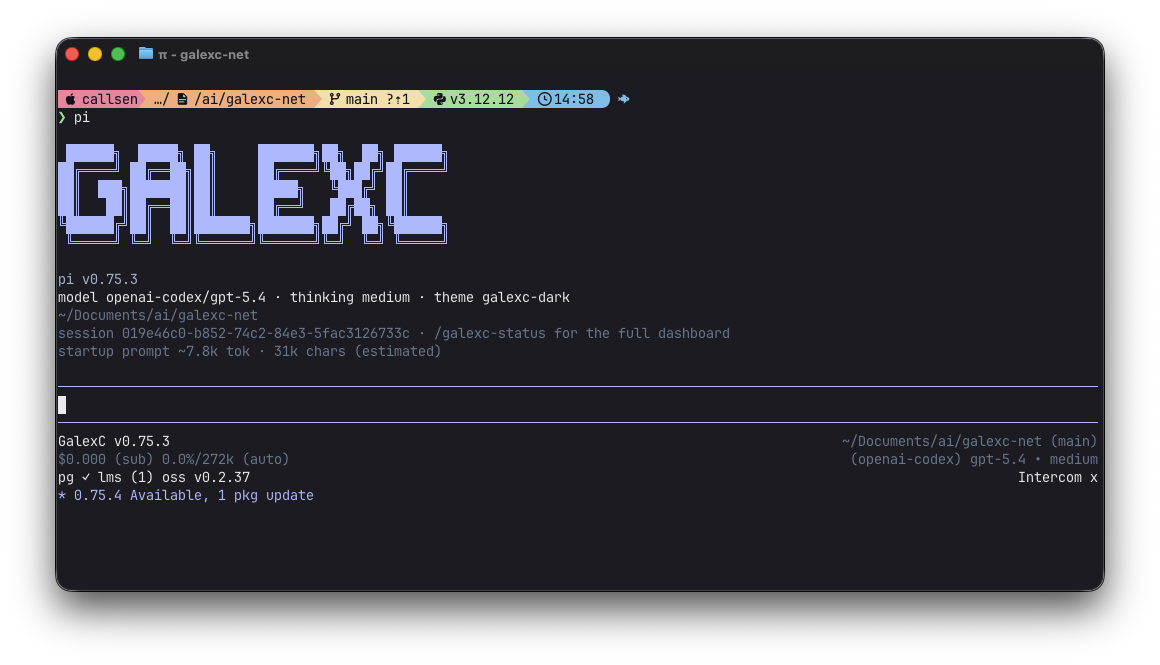
Another habit I’ve formed: If a tool call goes sideways, I nearly always treat that as a context problem until proven otherwise. I’ll ensure that I take the time in that exact session to diagnose the issue and identify if it could have been prevented with a tweak to context content or routing.
I rely on routing alomst more than the context itself. That is probably the biggest behavioral shift. I used to be more tolerant of stuffing extra context into a session because it felt like insurance. I am much less tolerant of that now. If a workflow is real, it should have a route. If a lesson keeps recurring, it should move into expertise. If a startup file is carrying detail that only matters one time in twenty, it probably belongs behind a sharper pointer.
I also try to keep the system honest by making context changes inspectable. That’s why I spent the time to both measure and display the startup context front-and-center in my workstation pi sessions and why I wanted the audit capability to exist as a first-class skill instead of a one-off cleanup session I would half-remember later.
None of this feels finished to me, which is likely why I enjoy it :) To be clear, I don’t have a grand theory of perfect agent context. I want a system that can keep tightening toward deterministic behavior while leveraging this incredible non-deterministic tech - and context management has been a big lever in that regard.
In summary
I am happy with the system as it stands right now, which focuses on:
- Small layered startup context.
- Sharp ownership boundaries.
- Aggressive routing.
- Visible context feedback.
- Expertise as maintained memory.
This will continue to evolve, so the interesting work here is not freezing this pattern but staying close enough to the context to understand what toggles matter.