Published dispatch May 9, 2026
Learning to Love Upgrades
Dependency upkeep feels very different once upgrades are part of the happy path and the system already has the backups, restore paths, and visibility to make them routine.
I don't necessarily enjoy dependency management for its own sake, especially because it often cuts into whatever I thought I would be building that day. I have learned to appreciate what frequent upgrades do to a system when the foundations are right, though. If backups, restore paths, and visibility are already designed in, staying current stops feeling like a disruption and starts feeling like normal operation, with the occasional genuinely fun new feature.
Filed
May 9, 2026
Published on galexc.me/dispatches
Read time
10 min
A practical pass on agent behavior.
Tags
Editorial note
Co-authored by Gilman and GalexC.
upgrade posture
Some high level stats before the long-form writeup.
Software is either being actively maintained or it is slowly dying, as the saying goes. I think this is even more true today, given the pace of AI-driven development cycles. Part of active maintenance means keeping your dependencies up to date. It's easy to treat upgrades as an interruption, something to dread, defer, and eventually negotiate with when a version finally becomes unsupported or starts turning into a liability.
If I don't take the time to know which dependencies are essential, if I carry too many of them, or if I only look at them when something breaks, the whole system gets more fragile and every update turns into a PITA. I want to avoid that.
This is a reflection on how I keep GalexC's essential dependencies current by minimizing the list, pinning them in repo, watching them live in Hub Web, and treating upgrades as first-class system work instead of deferred cleanup.
Dependency upkeep isn’t separate from the real work, it’s part of the happy path for software. If the stack underneath my agents, search, CI, storage, and observability quietly drifts out of support, the interesting workflows on top stop mattering.
I do get some real enjoyment out of upgrading core services, which I realize is a little odd. But the bigger point is that GalexC is set up to make dependency work legible, routine, and occasionally fun.
Visibility changes the emotional shape of maintenance.
Keep the list short
The best dependency strategy is not heroic upgrade discipline. It is having fewer essential things to worry about.
That sounds obvious, but it changes how I build. If something doesn’t need to be a permanent part of the stack, I don’t want it there. Every extra runtime, sidecar, image, and hosted service becomes one more thing that can go unsupported, one more release feed to watch, and one more migration path to remember when I least want to.
That is also why I like keeping the source of truth in repo. Ansible defaults, image pins, and checker metadata tell me what the system depends on in a way memory never will.
COMPONENTS = [
ComponentDef(name="forgejo", latest_url=".../forgejo/releases?limit=20"),
ComponentDef(name="meilisearch", github_repo="meilisearch/meilisearch"),
ComponentDef(name="cadvisor", latest_url="https://gcr.io/v2/cadvisor/cadvisor/tags/list"),
...
]That little pattern matters. If a thing is essential, it should have an explicit slot in the list. If it’s not in the list, I should be able to say why.
The versions panel made the habit stick
The Hub Web component versions panel is the part that made this habit stick because I don’t want to (can’t) carry dependency state in my head. Instead, I want one place that tells me what is current, what is stale, and when that answer was last checked.
This post was inspired by an incredible experience updating GalexC dependencies yesterday. On the night of these upgrades, this panel showed eight of thirteen tracked components that were outdated. I got a gratifying list of all green dependencies with only two Pi sessions and essentially zero manual work.
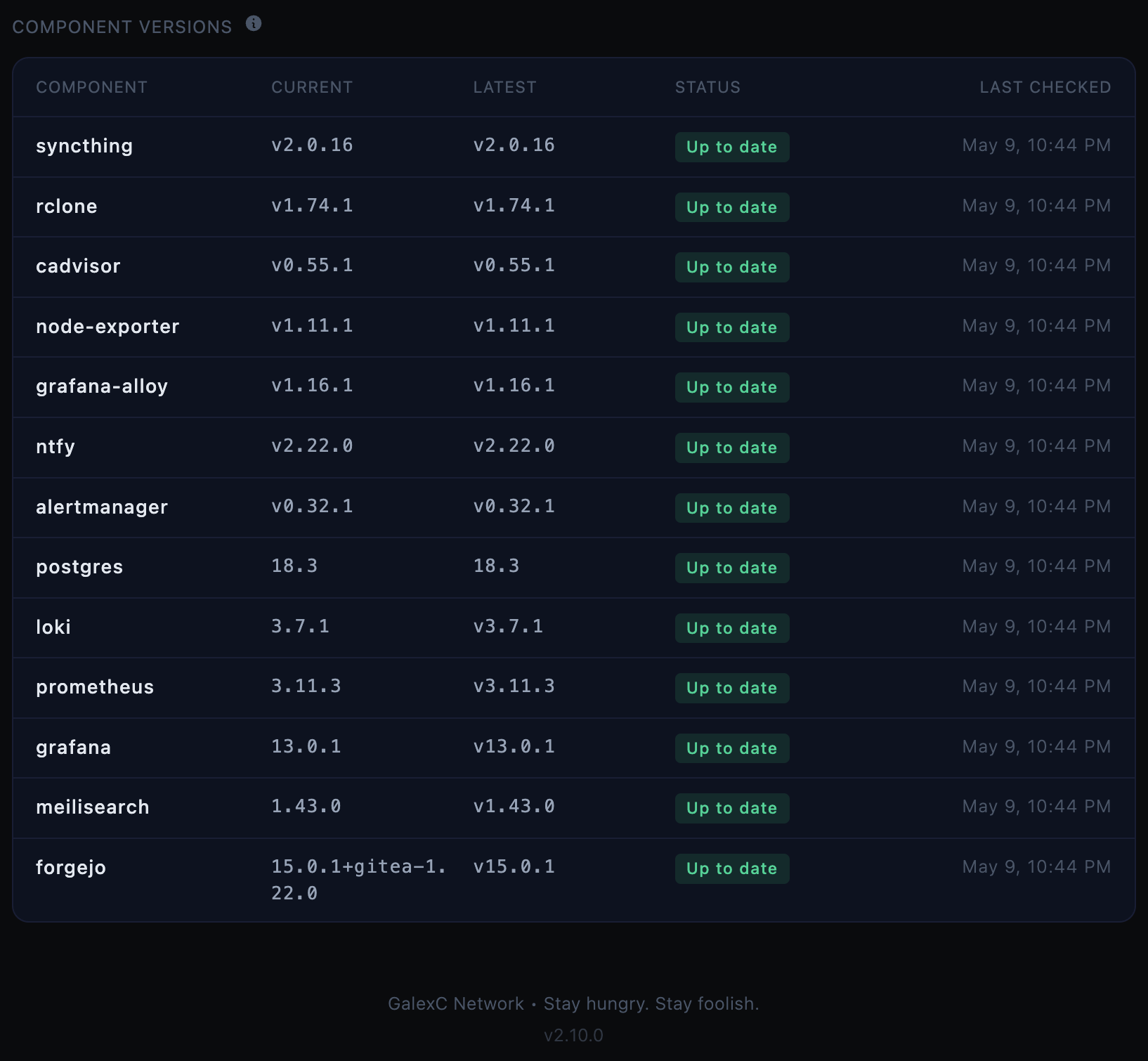
The underpinning GalexC dependency management system (potentially a future post will go into detail here, if of interest) makes this possible. If one thing is stale, I can usually take it in one shot. If several things are stale, I can group the safe ones and isolate the stateful one. If the dashboard says everything is current, I stop thinking about it and go build something else.
It also changes the mood. Upgrades stop feeling like a special category of bad news and start feeling like ordinary system care.
Direct visibility also keeps me honest about where visibility stops. Some dependencies are easy to query live. Others are pinned-only and need repo metadata because they don’t expose a useful version API. That distinction isn’t a weakness. It’s just reality written down.
The easy upgrades are only easy because the system tells the truth
One of the May 9 sessions was the kind of upgrade pass people like to imagine all upgrade work should be: take the outdated list, batch the straightforward services, apply the role changes, and move on.
What made it feel different was how little I had to say. GalexC nailed it.
Most of it really was routine. The useful part is that the routine surfaced three places where the system was lying.
| Reported | What was actually true | Fix |
|---|---|---|
cAdvisor looked ready for v0.56.2 | The checker was reading GitHub releases even though the deployable image tags live in GCR. | Switch latest-version tracking to the GCR tags endpoint and pin the real latest image, v0.55.1. |
| Meilisearch looked blocked on disk space | The guard counted the whole data directory, including dump artifacts that did not need to be duplicated. | Measure the active data.ms payload instead of the entire directory before deciding whether the migration is safe. |
| Snapshot cleanup looked fine | The cleanup path was pointed at the wrong parent directory, so old Meilisearch data directories would have accumulated. | Correct the path while the migration context was already in hand. |
None of that is glamorous, but it’s why I’m serious about version visibility. Every upgrade pass is a proof exercise for whether my understanding of the system is still correct.
The hard upgrade was one design prompt and then a single-shot implementation prompt
The other May 9 session was the opposite kind of dependency work: Forgejo 15. That upgrade took about four hours, touched the repo host and the runner, and couldn’t be treated like a casual image bump because the old 14.x line had already fallen out of support.
This is the kind of upgrade people remember when they say they hate maintenance, and they’re not wrong. Stateful systems with CI attached are exactly where version drift gets expensive. But this is also where foundations pay you back. If the backup path, restore path, and validation checklist already exist, the hard upgrade is still work, but it isn’t chaos.
What I like about this session is that the execution still happened in one controlled shot. The one-shot part was earned. The design happened first in a task: runner compatibility research, rollback posture, cookie preservation, backup expectations, and validation gates were all written down before touching production.
The repo diff itself was almost boring:
forgejo_image: codeberg.org/forgejo/forgejo:15.0.1
forgejo_cookie_remember_name: gitea_incredibleThat is exactly why it is interesting. The visible change was small because the real work lived in the safety posture around it.
That is the part I mean by learning to love upgrades. The safety machinery is already there, so I’m not inventing caution from scratch every time. I get to use the same foundational systems thinking I needed anyway.
How I actually use this
I check the versions panel because I don’t want dependency awareness to rely on memory or mood. If the dashboard is green, great. If something is stale, I am aware of it with zero effort. I can decide when it’s worth a maintenance run - typically when a number of patch releases have occurred and definitely when a major version has happened. If the list starts to get too yellow, that is a signal that I’m letting too much essential surface area accumulate.
I classify the work quickly. Some upgrades are ordinary pin bumps plus smoke tests. Some are migrations and need design first. Mixing those two modes is how you end up turning a ten minute maintenance task into a midnight recovery exercise.
And I take the upside seriously too. Staying current means the improvements land while they’re still fresh. The recent Grafana move to 13 was a good reminder because it included new AI-focused goodies.
I keep the list itself under scrutiny too. Every component on that dashboard is a small tax I’ve accepted. If one of them stops pulling its weight, the right answer might not be to keep upgrading it forever. The right answer might be to delete it.
What I learned
Keeping dependencies current is essential because support windows, security fixes, and behavioral changes don’t care whether I’m busy with something more interesting. They keep moving anyway.
The only sustainable answer I know is to make upgrades part of the happy path. Minimize the set of essential dependencies. Pin them where the repo can see them. Build the backups, restore paths, and checks once so they’re there when you need them. Give yourself a live board that tells the truth. Then each upgrade becomes a proof exercise instead of a crisis.
That is the part worth loving: running a system where staying current is normal.
Update, May 18: Nine days later, the versions panel was already lighting back up.
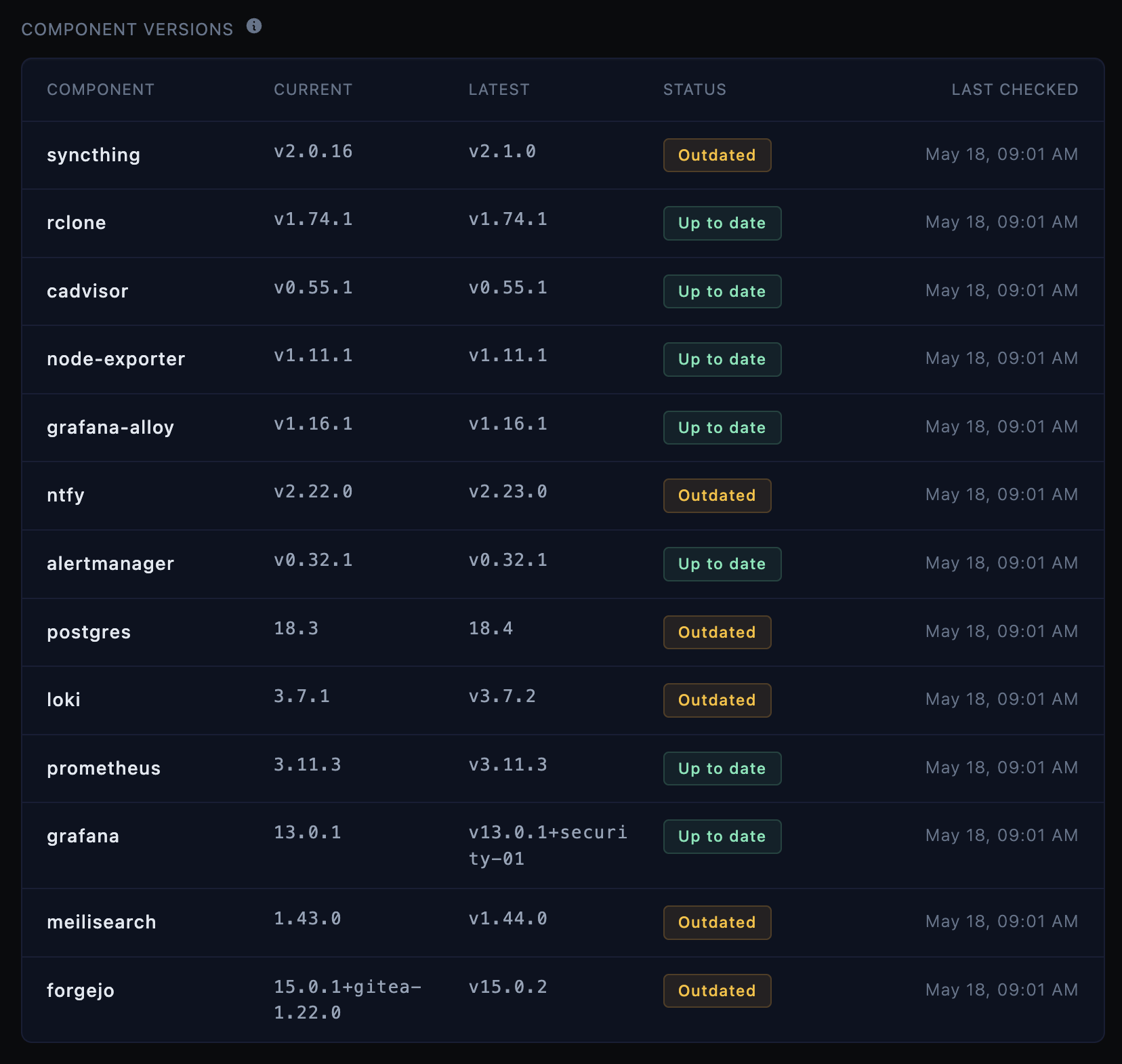
That screenshot is a good example of the system doing its job. It checked the fleet, compared current pins against live latests, and surfaced the drift without me having to go looking for it. It is also a useful reminder of how fast this moves. You get things green, and a week later several components already have fresh releases waiting.
P.S. This is also why Stewart Brand’s recent book Maintenance: Of Everything, Part One caught my eye. Maintenance is not the work you do after the real work. It is a big part of what makes the real work possible.